
Machine Learning Research Requires Smaller Sample Sizes than Previously Thought
In this post, authors Louis Hickman, Josh Liff, Caleb Rottman, and Charles Calderwood outline the inspiration behind their recently published academic paper, “The Effects of the Training Sample Size, Ground Truth Reliability, and NLP Method on Language-Based Automatic Interview Scores’ Psychometric Properties,” found in Organizational Research Methods.
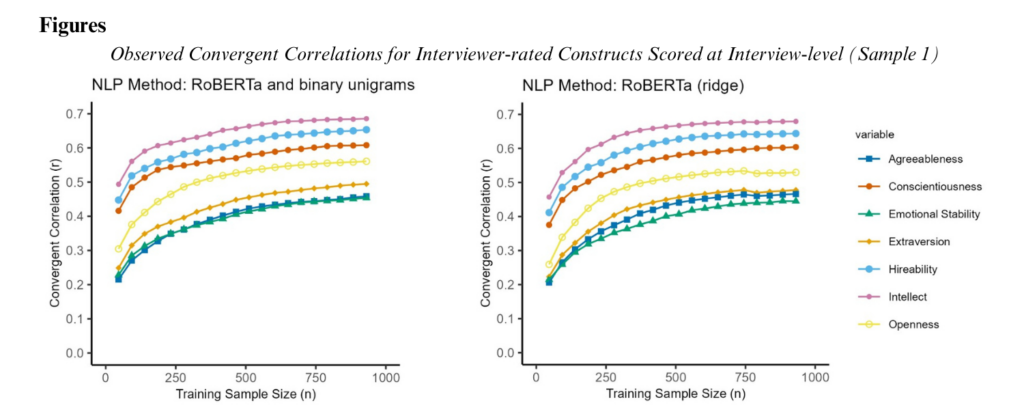
Natural language processing (NLP) and supervised machine learning (ML) are increasingly used to score latent constructs from natural language text in both research and practice (e.g., personnel selection). However, many practitioners, researchers, and reviewers assume that ML requires thousands of observations. Our research aimed to empirically address this assumption, given that editors and reviewers have previously pressed us to obtain larger sample sizes.
Thus, we designed an experiment to understand how training sample size, NLP method, and reliability of the target variable affect the convergent validity and test-retest reliability of ML scores in the context of automatically scored interviews. We were surprised to find that for most target variables, neither validity nor reliability increased much when the ML training data included at least 500 observations. Researchers can pursue projects on NLP and ML with just hundreds of observations, thereby significantly lowering the barrier to entry in this emerging area of research.
Researchers and practitioners are already using large language models (LLMs), such as those that power ChatGPT, to score psychological constructs from text with little (few-shot) to no (zero-shot) additional training data. Many organizations will continue to opt for traditional, supervised ML models for scoring open-ended content because they control the model and its training data and can adjust the model to improve fairness. On the other hand, some LLMs have not shared their training data, no known methods can reduce bias in their outputs, and most organizations do not have the resources ($$$) to train an LLM from scratch.
LLMs have lowered the barrier for getting started in this area of research, as they can help researchers and practitioners write and learn how to code. Combining NLP with ML is a powerful way to capitalize on the voluminous amounts of unstructured data relevant to organizations. Additional guidance and example code for getting started is available in the following publications.
Hickman, L., Saef, R., Ng, V., Tay, L., Woo, S. E., & Bosch, N. (2021). Developing and evaluating language-based machine learning algorithms for inferring applicant personality in video interviews. Human Resource Management Journal, advance online publication. https://doi.org/10.1111/1748-8583.12356
Hickman, L., Thapa, S., Tay, L., Cao, M., & Srinivasan, P. (2022). Text preprocessing for text mining in organizational research: Review and recommendations. Organizational Research Methods, 25(1), 114-146. https://doi.org/10.1177/1094428120971683
Rottman, C., Gardner, C., Liff, J., Mondragon, N., & Zuloaga, L. (2023). New strategies for addressing the diversity–validity dilemma with big data. Journal of Applied Psychology, 108(9), 1425–1444. https://doi.org/10.1037/apl0001084
Zhang, N. Wang, M., Xu, H., Koenig, N., Hickman, L., Kuruzovich, J., Ng, V., Arhin, K., Wilson, D., Song, Q. C., Tang, C., Alexander, L., & Kim, Y. (2023). Reducing Subgroup Differences in Personnel Selection through the Application of Machine Learning. Personnel Psychology, 76(4), 1125-1159. https://doi.org/10.1111/peps.12593



























































































